
高性能库表设计
范式和反范式
范式
范式是关系数据库理论的基础,也是我们在设计数据库结构过程中所要遵循的规则和指导方法。数据库的设计范式是数据库设计所需要满足的规范。只有理解数据库的设计范式,才能设计出高效率、优雅的数据库,否则可能会设计出低效的库表结构。目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,还又称完美范式。
满足最低要求的叫第一范式,简称1NF。在第一范式基础上进一步满足一些要求的为第二范式,简称2NF。其余依此类推。各种范式呈递次规范,越高的范式数据库冗余越小。通常所用到的只是前三个范式,即:第一范式(1NF),第二范式(2NF),第三范式(3NF)。
第一范式
第一范式无重复的列,表中的每一列都是拆分的基本数据项,即列不能够再拆分成其他几列,强调的是列的原子性。
如果在实际场景中,一个联系人有家庭电话和公司电话,那么以“姓名、性别、电话”为表头的表结构就没有达到1NF。要符合1NF我们只需把电话列拆分,让表头变为姓名、性别、家庭电话、公司电话即可。
第二范式
属性完全依赖于主键,首先要满足它符合1NF,另外还需要包含两部分内容:
- 表必须有一个主键;
- 没有包含在主键中的列必须完全依赖于主键,而不能只依赖于主键的一部分。即要求实体的属性完全依赖于主关键字。所谓完全依赖是指不能存在仅依赖主关键字一部分的属性。
第三范式
第三范式属性不传递依赖于其他非主属性,首先需要满足 2NF,另外非主键列必须直接依赖于主键,不能存在传递依赖。即不能存在:非主键列 A 依赖于非主键列 B,非主键列 B 依赖于主键的情况。
第二范式和第三范式的区别第二范式:
- 非主键列是否依赖主键(包括一列通过某一列间接依赖主键),要是有依赖关系就是第二范式;
- 第三范式:非主键列是否直接依赖主键,不能是那种通过传递关系的依赖。要是符合这种依赖关系就是第三范式。通过对前三个范式的了解,我们知道 3NF 是 2NF 的子集,2NF 是 1NF 的子集。
范式优缺点
优点:
- 避免数据冗余,减少维护数据完整性的麻烦;
- 减少数据库的空间;
- 数据变更速度快。
缺点:
- 按照范式的规范设计的表,等级越高的范式设计出来的表数量越多。
- 获取数据时,表关联过多,性能较差。
表的数量越多,查询所需要的时间越多。也就是说所用的范式越高,对数据操作的性能越低。
反范式
范式是普适的规则,满足大多数的业务场景的需求。对于一些特殊的业务场景,范式设计的表,无法满足性能的需求。此时,就需要根据业务场景,在范式的基础之上进行灵活设计,也就是反范式设计。
反范式设计主要从三方面考虑:
业务场景,相应时间,字段冗余。
反范式设计就是用空间来换取时间,提高业务场景的响应时间,减少多表关联。主要的优点如下:
允许适当的数据冗余,业务场景中需要的数据几乎都可以在一张表上显示,避免关联;
可以设计有效的索引。
范式与反范式异同
范式化模型:数据没有冗余,更新容易;当表的数量比较多,查询数据需要多表关联时,会导致查询性能低下。
反范式化模型:冗余将带来很好的读取性能,因为不需要join很多很多表;虽然需要维护冗余数据,但是对磁盘空间的消耗是可以接受的。
MySQL 使用原则和设计规范
概述
MySQL虽然具有很多特性并提供了很多功能,但是有些特性会严重影响它的性能,比如,在数据库里进行计算,写大事务、大SQL、存储大字段等。想要发挥MySQL的最佳性能,需要遵循3个基本使用原则。
- 首先是需要让MySQL回归存储的基本职能:MySQL数据库只用于数据的存储,不进行数据的复杂计算,不承载业务逻辑,确保存储和计算分离;
- 其次是查询数据时,尽量单表查询,减少跨库查询和多表关联;
- 还有就是要杜绝大事务、大 SQL、大批量、大字段等一系列性能杀手。
补充:
大事务,运行步骤较多,涉及的表和字段较多,容易造成资源的争抢,甚至形成死锁。一旦事务回滚,会导致资源占用时间过长。
大SQL,复杂的SQL意味着过多的表的关联,MySQL数据库处理关联超过3张表以上的SQL时,占用资源多,性能低下。
大批量,意味着多条SQL一次性执行完成,必须确保进行充分的测试,并且在业务低峰时段或者非业务时段执行。大字段,blob、text等大字段,尽量少用。必须要用时,尽量与主业务表分离,减少对这类字段的检索和更新。
下面具体讲解数据库的基本设置规则:
- 必须指定默认存储引擎为InnoDB,并且禁用MyISAM存储引擎,随着MySQL8.0版本的发布,所有的数据字典表都已经转换成了InnoDB,MyISAM存储引擎已成为了历史。
- 默认字符集UTF8mb4,以前版本的UTF8是UTF8mb3,未包含个别特殊字符,新版本的UTF8mb4包含所有字符,官方强烈建议使用此字符集。
- 关闭区分大小写功能。设置lower_case_tables_name=1,即可关闭区分大小写功能,即大写字母 T 和小写字母 t 一样。
MySQL数据库提供的功能很全面,但并不是所有的功能性能都高效。
- 存储过程、触发器、视图、event。为了存储计算分离,这类功能尽量在程序中实现。这些功能非常不完整,调试、排错、监控都非常困难,相关数据字典也不完善,存在潜在的风险。一般在生产数据库中,禁止使用。
- lob、text、enum、set。这些字段类型,在MySQL数据库的检索性能不高,很难使用索引进行优化。如果必须使用这些功能,一般采取特殊的结构设计,或者与程序结合使用其他的字段类型替代。比如:set 可以使用整型(0,1,2,3)、注释功能和程序的检查功能集合替代。
规范命名
统一的规范命名,可以增加可读性,减少隐式转换。
命名时的字符取值范围为:az,09 和 _(下画线)。
-
所有表名小写,不允许驼峰式命名;
-
允许使用 -(横线)和 (空格);如下图所示,当使用 -(横线),后台默认会转化成 @002d;
-
不允许使用其他特殊字符作为名称,减少潜在风险。
数据库库名的命名规则必须遵循“见名知意”的原则,即库名规则为“数据库类型代码 + 项目简称 + 识别代码 + 序号”。
表名的命名规则分为:
单表仅使用 a~z、_;
分表名称为“表名_编号”;
业务表名代表用途、内容:子系统简称_业务含义_后缀。
常见业务表类型有:临时表,tmp;备份表,bak;字典表,dic;日志表,log。
字段名精确,遵循“见名知意”的原则,格式:名称_后缀。
- 避免普遍简单、有歧义的名称。用户表中,用户名的字段为 UserName 比 Name 更好。
- 布尔型的字段,以助动词(has/is)开头。用户是否有留言 hasmessage,用户是否通过检查 ischecked 等。
索引命名格式,主要为了区分哪些对象是索引:
前缀_表名(或缩写)_字段名(或缩写);主键必须使用前缀“pk_”;UNIQUE约束必须使用前缀“uk_”;普通索引必须使用前缀“idx_”。
表创建的注意事项
- 主键列,UNSIGNED整数,使用auto_increment;禁止手动更新auto_increment,可以删除。
- 必须添加comment注释。
- 必须显示指定的engine。
- 表必备三字段:id、xxx_create、xxx_modified。
- id为主键,类型为unsignedbigint等数字类型;
- xxx_create、xxx_modified的类型均为 datetime 类型,分别记录该条数据的创建时间、修改时间。
备份表/临时表等常见表的设计规范
- 备份表,表名必须添加bak和日期,主要用于系统版本上线时,存储原始数据,上线完成后,必须及时删除。
- 临时表,用于存储中间业务数据,定期优化,及时降低表碎片。
- 日志类表,首先考虑不入库,保存成文件,其次如果入库,明确其生命周期,保留业务需求的数据,定期清理。
- 大字段表,把主键字段和大字段,单独拆分成表,并且保持与主表主键同步,尽量减少大字段的检索和更新。
- 大表,根据业务需求,从垂直和水平两个维度进行拆分。
字段设计要求
- 根据业务场景需求,选择合适的类型,最短的长度;确保字段的宽度足够用,但也不要过宽。所有字段必须为NOTNULL,空值则指定default值,空值难以优化,查询效率低。比如:人的年龄用unsignedtinyint(范围0~255,人的寿命不会超过255岁);海龟就必须是smallint,但如果是太阳的年龄,就必须是int;如果是所有恒星的年龄都加起来,那么就必须使用bigint。
- 表字段数少而精,尽量不加冗余列。
- 单实例表个数必须控制在 2000 个以内。
- 单表分表个数必须控制在 1024 个以内。
- 单表字段数上限控制在 20~50 个。
**禁用ENUM、SET类型。**兼容性不好,性能差。
解决方案:使用TINYINT,在COMMENT信息中标明被枚举的含义。`is_disable` TINYINT UNSIGNED DEFAULT’0’COMMENT '0:启用1:禁用2:异常’。
**禁用列为NULL。**MySQL难以优化NULL列;NULL列加索引,需要额外空间;含NULL复合索引无效。
解决方案:在列上添加 NOT NULL DEFAULT 缺省值。
**禁止 VARBINARY、BLOB 存储图片、文件等。**禁止在数据库中存储大文件,例如照片,可以将大文件存储在对象存储系统中,数据库中存储路径。
不建议使用TEXT/BLOB:处理性能差;行长度变长;全表扫描代价大。
解决方案:拆分成单独的表。
存储字节越小,占用空间越小。尽量选择合适的整型,如下图所示。
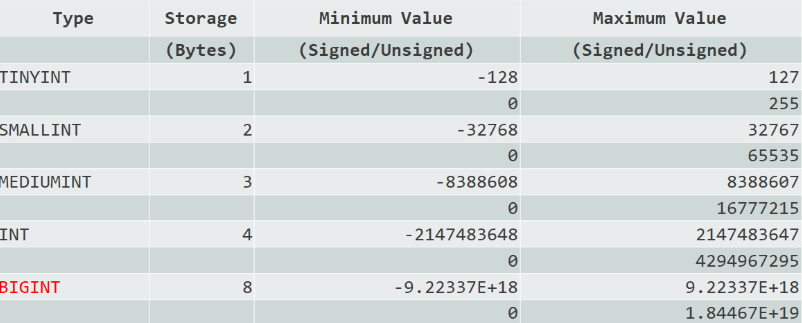
建议:
- 主键列,无负数,建议使用INTUNSIGNED或者BIGINTUNSIGNED;预估字段数字取值会超过42亿,使用BIGINT类型。
- 短数据使用TINYINT或SMALLINT,比如:人类年龄,城市代码。
- 使用 UNSIGNED 存储非负数值,扩大正数的范围。
推荐字符集都为 UTF8mb4,中文存储占三个字节,而数据或字母,则只占一个字节。
CHAR(N) 和 VARCHAR(N) 的长度 N,不是字节数,是字符数。
例:username VARCHAR(40):username 最多能存储 40 个字符,占用 120 个字节。
Char 与 Varchar 类型
存储字符串长度相同的全部使用 Char 类型;字符长度不相同的使用 Varchar 类型,不预先分配存储空间,长度不要超过 255。
案例处理
IP处理
一般使用Char(15)进行存储,但是当进行查找和统计时,字符类型不是很高效。MySQL数据库内置了两个IP相关的函数INET_ATON()、INET_NTOA(),可以以实现 IP 地址和整数的项目转换。
因此,我们使用 INT UNSIGNED(占用 4 个字节)存储 IP。
将 IP 的存储从字符型转换成整形,转化后数字是连续的,提高了查询性能,使查询更快,占用空间更小。
TIMESTAMP处理
同样的方法,我们使用MySQL内置的函数(FROM_UNIXTIME(),UNIX_TIMESTAMP()),可以将日期转化为数字,用INTUNSIGNED存储日期和时间。
高性能索引设计
索引概述
数据库索引是一种数据结构,它以额外的写入和存储空间为代价来提高数据库表上数据检索操作的速度。通俗来说,索引类似于书的目录,根据其中记录的页码可以快速找到所需的内容。
MySQL官方对索引(Index)的定义是存储引擎用于快速查找记录的一种数据结构。
- 索引是物理数据页,数据库页大小(PageSize)决定了一个页可以存储多少个索引行,以及需要多少页来存储指定大小的索引。
- 索引可以加快检索速度,但同时也降低索引列插入、删除、更新的速度,索引维护需要代价。
索引原理
二分查找是索引实现的理论基础。在数据库中大部分索引都是通过 B+Tree 来实现的。当然也涉及其他数据结构,在 MySQL 中除了 B+Tree 索引外我们还需要关注下 Hash 索引。
Hash 索引
哈希表是数据库中哈希索引的基础,是根据键值<key,value>存储数据的结构。简单说,哈希表是使用哈希函数将索引列计算到桶或槽的数组,实际存储是根据哈希函数将key换算成确定的存储位置,并将 value 存放到该数组位置上。访问时,只需要输入待查找的 key,即可通过哈希函数计算得出确定的存储位置并读取数据。
Hash 索引的实现
数据库中哈希索引是基于哈希表实现的,对于哈希索引列的数据通过Hash算法计算,得到对应索引列的哈希码形成哈希表,由哈希码及哈希码指向的真实数据行的指针组成了哈希索引。哈希索引的应用场景是只在对哈希索引列的等值查询才有效。
因为哈希索引只存储哈希值和行指针,不存储实际字段值,所以其结构紧凑,查询速度也非常快,在无哈希冲突的场景下访问哈希索引一次即可命中。但是哈希索引只适用于等值查询,包括=、IN()、<=>(安全等于,selectnull<=>null和selectnull=null是不一样的结果),不支持范围查询。
Hash碰撞的处理
Hash碰撞是指不同索引列值计算出相同的哈希码,表中字段为A和B两个不同值根据Hash算法计算出来的哈希码都一样就是出现了哈希碰撞。对于 Hash 碰撞通用的处理方法是使用链表,将 Hash 冲突碰撞的元素形成一个链表,发生冲突时在链表上进行二次遍历找到数据。
MySQL 中如何使用 Hash 索引?
在 MySQL 中主要是分为 Memory 存储引擎原生支持的 Hash 索引 、InnoDB 自适应哈希索引及 NDB 集群的哈希索引3类。
InnoDB自适应哈希索引是为了提升查询效率,InnoDB存储引擎会监控表上各个索引页的查询,当InnoDB注意到某些索引值访问非常频繁时,会在内存中基于B+Tree索引再创建一个哈希索引,使得内存中的 B+Tree 索引具备哈希索引的功能,即能够快速定值访问频繁访问的索引页。
为什么要为B+Tree索引页二次创建自适应哈希索引呢?这是因为B+Tree索引的查询效率取决于B+Tree的高度,在数据库系统中通常B+Tree的高度为3~4层,所以访问数据需要做 3~4 次的查询。而 Hash 索引访问通常一次查找就能定位数据(无 Hash 碰撞的情况),其等值查询场景 Hash 索引的查询效率要优于 B+Tree。
自适应哈希索引的建立使得InnoDB存储引擎能自动根据索引页访问的频率和模式自动地为某些热点页建立哈希索引来加速访问。另外InnoDB自适应哈希索引的功能,用户只能选择开启或关闭功能,无法进行人工干涉。功能开启后可以通过 Show Engine Innodb Status 看到当前自适应哈希索引的使用情况。
B+Tree 索引
如下图所示为一个简单的、标准的 B+tree,每个节点有 K 个键值和 K+1 个指针。
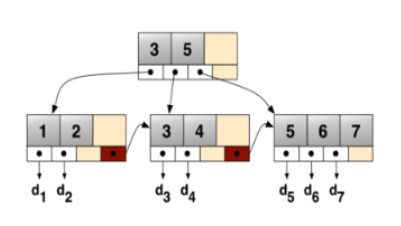
B+Tree索引能够快速访问数据,就是因为存储引擎可以不再需要通过全表扫描来获取数据,而是从索引的根结点(通常在内存中)开始进行二分查找,根节点的槽中都存放了指向子节点的指针,存储引擎根据这些指针能快速遍历数据。
叶子节点存放的 <key+data> ,对于真正要存放哪些数据还得取决于该 B+Tree 是聚簇索引(Clustered Index)还是辅助索引(Secondary Index)。
聚簇索引和辅助索引
聚簇索引是一种数据存储方式,它表示表中的数据按照主键顺序存储,是索引组织表。InnoDB的聚簇索引就是按照主键顺序构建B+Tree,B+Tree的叶子节点就是行记录,数据行和主键值紧凑地存储在一起。这也意味着InnoDB的主键索引就是数据表本身,它按主键顺序存放了整张表的数据。而InnoDB辅助索引(也叫作二级索引)只是根据索引列构建B+Tree,但在B+Tree的每一行都存了主键信息,加速回表操作。
聚簇索引占用的空间就是整个表数据量的大小,而二级索引会比聚簇索引小很多, 通常创建辅助索引就是为了提升查询效率。
在MySQLInnoDB中索引通常可以分为两大类:主键索引(即聚簇索引)和辅助索引(非聚簇索引)。对于没有指定主键的表,InnoDB会自己选择合适字段为主键,其选择顺序如下:
- 显式主键;
- 第一个唯一索引(要求唯一索引所有列都非 NULL);
- 内置的 6 字节 ROWID。
建议使⽤ UNSIGNED 自增列显示创建主键。
联合索引和覆盖索引
根据索引列个数和功能描述不同索引也可以分为:联合索引和覆盖索引。
- 联合索引是指在多个字段联合组建索引的。
- 当通过索引即可查询到所有记录,不需要回表到聚簇索引时,这类索引也叫作覆盖索引。
- 主键查询是天然的覆盖索引,联合索引可以是覆盖索引。
那么如何看SQL语句是否使用到覆盖索引了呢?通常在查看执行计划时,Extra列为Usingindex则表示优化器使用了覆盖索引。
我们通常建议优先考虑使用覆盖索引,这是因为如果SQL需要查询辅助索引中不包含的数据列时,就需要先通过辅助索引查找到主键值,然后再回表通过主键查询到其他数据列(即回表查询),需要查询两次。而覆盖索引能从索引中直接获取查询需要的所有数据,从⽽避免回表进行二次查找,节省IO,效率较⾼。
索引使用技巧
接下来聊一聊索引使用技巧的基础知识,这些知识可以帮助你建立高效索引,主要有谓词、过滤因子、基数(Cardinality)、选择率和回表。
谓词和过滤因子
谓词本身就是条件表达式,通俗讲就是过滤字段。如下图中这句SQL语句,可以拆解为下面所示:
select * from city where city ='BeiJing' and last_updata = '2019-09-01'
简单谓词:city和last_updata。组合谓词:cityandlast_updata。
知道谓词后就可以计算谓词的过滤因子了,过滤因子直接描述了谓词的选择性,表示满足谓词条件的记录行数所占比例,过滤因子越小意味着能过滤越多数据,你需要在这类谓词字段上创建索引。
过滤因子的计算算法,就是满足谓词条件的记录行数除以表总行数。
- 简单谓词的过滤因子 = 谓词结果集的数量 / 表总行数
- 组合谓词的过滤因子 = 谓词 1 的过滤因子 × 谓词 2 的过滤因子
下面用一个例子来看下,如何快速根据SQL语句计算谓词、过滤因子。
- 根据SQL语句可以快速得到谓词信息:简单谓词 city 和 last_update,组合谓词 city and last_update。
- 计算每个谓词信息的过滤因子,过滤因子越小表示选择性越强,字段越适合创建索引。例如:
- city 的过滤因子=谓词 city 结果集的数量/表总行数=select count(*) from city where city = ‘BeiJing’ / select countt(*) from city = 20%;
- *last_update 的过滤因子 = 谓词 last_update 结果集的数量 / 表总行数 = select count(*) from city where last_update = ‘2019-08-01’ / select count(*) from city = 10%;
- 组合谓词 = city 过滤因子 * last_update 过滤因子 = 20% × 10% = 2%,组合谓词的过滤因子为 2%,即只有表总行数的 2% 匹配过滤条件,可以考虑创建组合索引 (city,last_update)。
基数和选择率
基数(Cardinality )是某个键值去重后的行数,索引列不重复记录数量的预估值,MySQL优化器会依赖于它。选择率是count (distinct city) / count(*),选择率越接近1则越适合创建索引,例如主键和唯一键的选择率都是 1。回表是指无法通过索引扫描访问所有数据,需要回到主表进行数据扫描并返回。
Cardinality 能快速告知字段的选择性,高选择性字段有利于创建索引。优化器在选择执行计划时会依赖该信息,通常这类信息也叫作统计信息,数据库中对于统计信息的采集是在存储引擎层进行的。
执行 show index from table_name会看到 Cardinality,同时也会触发 MySQL 数据库对 Cardinaltiy 值的统计。除此之外,还有三种更新策略。
- 触发统计:Cardinality 统计信息更新发生在 INSERT 和 UPDATE 时,InnoDB 存储引擎内部更新的 Cardinality 信息的策略为:1.表中超过1/16的数据发生变化;2.stat_modified_counter > 2000 000 000 (20亿)。
- 采样统计(sample):为了减少统计信息更新造成的资源消耗,数据库对 Cardinality 通过采样来完成统计信息更新,每次随机获取 innodb_stats_persistent_sample_pages 页的数量进行 Cardinality 统计。
- 手动统计:alter table table_name engine=innodb或 analyze table table_name,当发现优化器选择错误的执行计划或没有走理想的索引时,执行 SQL 语句来手动统计信息有时是一种有效的方法。
由于采样统计的信息是随机获取8个(8是由innodb_stats_transient_sample_pages参数指定)页面数进行分析,这就意味着下一次随机的8个页面可能是其他页面,其采集页面的 Carinality 也不同。因此当表数据无变化时也会出现 Cardinality 发生变化的情况。
索引使用细节
创建索引后如何确认SQL语句是否走索引了呢?创建索引后通过查看执行SQL语句的执行计划即可知道SQL语句是否走索引。执行计划重点关注跟索引相关的关键项,有type、possible_keys、key、key_len、ref、Extra 等。
其中,possible_keys 表示查询可能使用的索引,key表示真正实际使用的索引,key_len 表示使用索引字段的长度。另外执行计划中Extra选项也值得关注,例如Extra显示use index时就表示该索引是覆盖索引,通常性能排序的结果是use index>use where>use filsort
当索引选择组合索引时,通过计算key_len来了解有效索引长度对索引优化也是非常重要的,接下来重点讲解key_len计算规则。key_len表示得到结果集所使用的选择索引的长度[字节数],不包括orderby,也就是说如果orderby也使用了索引则key_len不计算在内。key_len计算规则从两个方面考虑,一方面是索引字段的数据类型,另一方面是表、字段所使用的字符集。
索引字段的数据类型,根据索引字段的定义可以分为变长和定长两种数据类型:
- 索引字段为定长数据类型,比如char、int、datetime,需要有是否为空的标记,这个标记需要占用1个字节;
- 对于变长数据类型,比如Varchar,除了是否为空的标记外,还需要有长度信息,需要占用两个字节。
表所使用的字符集,不同的字符集计算的 key_len 不一样,例如,GBK 编码的是一个占用 2 个字节大小的字符,UTF8 编码的是一个占用 3 个字节大小的字符。
通过key_len计算也帮助我们了解索引的最左前缀匹配原则。最左前缀匹配原则是指在使用B+Tree联合索引进行数据检索时,MySQL优化器会读取谓词(过滤条件)并按照联合索引字段创建顺序一直向右匹配直到遇到范围查询或非等值查询后停止匹配,此字段之后的索引列不会被使用,这时计算 key_len 可以分析出联合索引实际使用了哪些索引列。
设计高性能索引
- **定位由于索引不合适或缺少索引而导致的慢查询。**通常在业务建库建表时就需要提交业务运行相关的SQL给DBA审核,也可以借助ArkcontrolArkit来自动化审核。比如,慢查询日志分析,抓出运行慢的SQL进行分析,也可以借助第三方工具例如Arkcontrol慢查询分析系统进行慢查询采集和分析。在分析慢查询时进行参数最差输入,同时,对SQL语句的谓词进行过滤因子、基数、选择率和SQL查询回表情况的分析。
- 设计索引的目标是让查询语句运行得足够快,同时让表、索引维护也足够快,例如,使用业务不相关自增字段为主键,减缓页分裂、页合并等索引维护成本,加速性能。也可以使用第三方工具进行索引设计,例如Arkcontrol SQL 优化助手,会给出设计索引的建议。
- **创建索引策略:**优先为搜索列、排序列、分组列创建索引,必要时加入查询列创建覆盖索引;计算字段列基数和选择率,选择率越接近于1越适合创建索引;索引选用较小的数据类型(整型优于字符型),字符串可以考虑前缀索引;不要建立过多索引,优先基于现有索引调整顺序;参与比较的字段类型保持匹配并创建索引。
- **调优索引:**分析执行计划;更新统计信息(AnalyzeTable);Hint优化,方便调优(FORCEINDEX、USEINDEX、IGNOREINDEX、STRAIGHT_JOIN);检查连接字段数据类型、字符集;避免使用类型转换;关注 optimizer_switch,重点关注索引优化特性 MRR(Multi-Range Read)和 ICP(Index Condition Pushdown)。
- MRR优化是为了减少磁盘随机访问,将随机IO转化为顺序IO的数据访问,其方式是将查询得到辅助索引的键值放到内存中进行排序,通常是按照主键或RowID进行排序,当需要回表时直接根据主键或 RowID 排序顺序访问实际的数据文件,加速 SQL 查询。
- ICP优化同样也是对索引查询的优化特性,MySQL根据索引查询到数据后会优先应用where条件进行数据过滤,即无法使用索引过滤的where子句,其过滤由之前Server层的数据过滤下推到了存储引擎层,可以减少上层对记录的检索,提高数据库的整体性能。
创建索引规范
- 命名规范,各个公司内部统一。
- 考虑到索引维护的成本,单张表的索引数量不超过5个,单个索引中的字段数不超过5个。
- 表必需有主键,推荐使⽤UNSIGNED自增列作为主键。表不设置主键时InnoDB会默认设置隐藏的主键列,不便于表定位数据同时也会增大MySQL运维成本(例如主从复制效率严重受损、pt工具无法使用或正确使用)。
- 唯一键由3个以下字段组成,并且在字段都是整形时,可使用唯一键作为主键。其他情况下,建议使用自增列或发号器作主键。
- 禁止冗余索引、禁止重复索引,索引维护需要成本,新增索引时优先考虑基于现有索引进行rebuild,例如(a,b,c)和(a,b),后者为冗余索引可以考虑删除。重复索引也是如此,例如索引(a)和索引(a,主键ID) 两者重复,增加运维成本并占用磁盘空间,按需删除冗余索引。
- 联表查询时,JOIN 列的数据类型必须相同,并且要建⽴索引。
- 不在低基数列上建⽴索引,例如“性别”。 在低基数列上创建的索引查询相比全表扫描不一定有性能优势,特别是当存在回表成本时。
- 选择区分度(选择率)大的列建立索引。组合索引中,区分度(选择率)大的字段放在最前面。
- 对过长的Varchar段建立索引。建议优先考虑前缀索引,或添加CRC32或MD5伪列并建⽴索引。
- 合理创建联合索引,(a,b,c) 相当于 (a) 、(a,b) 、(a,b,c)。
- 合理使用覆盖索引减少IO,避免排序。
查询优化
MySQL采用基于开销的优化器,以确定处理查询的最佳方式,也就是说执行查询之前,都会先选择一条自以为最优的方案。在很多情况下,MySQL能够计算最佳的可能查询计划,但在某些情况下,MySQL没有关于数据的足够信息,或者是提供太多的相关数据信息,它所采用的可能并非就是事实上的最优方案。这里举了两个例子来说明。
案例一
Range Query Optimizer的流程
- 根据查询条件计算所有的 possible keys。
- 计算全表扫描代价(cost_all)。
- 计算最小的索引范围访问代价(这一步很关键,直接决定了 Range 的查询效率),它有三步:
- 对于每一个possible keys(可选索引),调用records_in_ranges函数计算范围中的rows;
- 根据rows,计算二级索引访问代价;
- 获取cost最小的二级索引访问(cost_range)。
- 选择执行最小化访问代价的执行计划。如果 cost_all <= cost_range,则全表扫描,否则索引范围扫描。
Range使用了records_in_range函数估算每个值范围的rows,结果依赖于possible_keys;possible_keys越多,随机IO代价越大,Range查询效率。所以,索引不是越多越好,相反,我们应该尽量减少possible_keys,减少records_in_range从而减少IO的消耗。这里给大家推荐两个工具,用pt-index-usage工具来删除冗余索引,用 pt-duplicate-key-checker 工具来删除重复索引。
案例二
优化前有一个索引idx_global_id。图中的这条SQL语句的where条件包括一个sub_id的等值查询和一个global_id的范围查询。执行一次需要2.37秒。从下一页的执行计划中,我们可以看到虽然查询优化器使用了唯一索引uniq_subid_globalid,但是由于idx_global_id的干扰,实际只使用了前面的4个长度就access,剩余8个长度都被filter了。
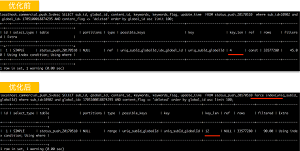
从优化后的执行计划中可以看到,使用了forceindex来强制使用唯一索引。正如上文列举的,相似的命令还有ignoreindex忽略索引,straght_join强制优化器按特定的顺序使强制优化器按特定的顺序使用数据表,high_priority 或 low_priority 两个命令来控制 SQL 的执行优先权。
ICP,MRR,BKA
1.ICPICP是IndexConditionPushdown的简称,是MySQL使用索引从表中检索行数据的一种优化方式。目的是减少从基表中全记录读取操作的数量,从而降低IO操作。
在没有开启ICP之前,存储引擎会通过遍历索引查找基表中的行,然后返回给MySQLServer层,再去为这些数据行进行where后的条件过滤。开启ICP之后,如果部分where条件能使用索引中的字段,MySQLServer会把这部分下推到存储引擎层,存储引擎通过索引过滤,把满足的行从表中读取出来。ICP能减少引擎层访问基表的次数和MySQLServer访问存储引擎的次数。对于 InnoDB 表来说,ICP 只适用于辅助索引.
2.MRR
MRR 是 Multi-Range Read 的简称,是 MySQL 优化器将随机 IO转化为顺序IO以降低查询过程中IO开销的一种手段。MRR的适用场景是辅助索引,如INDEX(key1),查询key1在n到m范围内的数据。使用限制就是MRR,MR适用于range、ref、eq_ref的查询。
3.BKA和BNLBKA是BatchedKeyAccess的简称,是MySQL优化器提高表join性能的一种手段,它是一种算法。而BNL是BlockNestedLoop的简称,它是默认的处理表join的方式和算法。那么二者有什么区别呢?
•BNL比BKA出现的早,BKA直到MySQL 5.6 版本才出现,而 BNL 至少在 MySQL 5.1 版本中就存在了;
• BNL 主要用于被 join 的表上无索引时;
• BKA 只在被 join 表上有索引时可以使用,那么就在行提交给被 join 的表之前,对这些行按照索引字段进行排序,因此减少了随机 IO,排序才是两者最大的区别,但如果被 join 的表没有索引呢?那么就只能使用 BNL 了。
使用BKA需要注意一些问题,比如:BKA的适用场景支持inner join、outer join、semi-join operations、including nested outer joins等;
BKA 有两个使用限制,一个是使用 BKA 特性,必须启用 MRR 特性;二是 BKA 主要适用于 join 的表上有索引可使用的情况,否则只能使用 BNL。
MySQL执行计划分析三部曲
当有慢查询或者执行 SQL 遇到瓶颈时,我们分析这类问题时可以参考 MySQL 执行计划分析“三步曲”。
- 查看 SQL 执行计划:
- explain SQL;
- desc 表名;
- show create table 表名。
- 通过 Profile 定位 QUERY 代价消耗:
- setprofiling=1;
- 执行SQL;
- show profiles;获取Query_ID。
- show profile for query Query_ID;查看详细的profile信息
- 通过Optimizer Trace表查看SQL执行计划树:
- set session optimizer_trace = ‘enabled = on’;
- 执行SQL;
- 查询information_schema.optimizer_trace 表,获取 SQL 查询计划树;
- set session optimizer_trace=‘enabled=off’;开启此项影响性能,记得用后关闭。
查询相关参数和分析工具
MySQL 可以通过设置一些参数,将运行时间长或者非索引查找的 SQL 记录到慢查询文件中。可以分析慢查询文件中的 SQL,有针对性的进行优化。
- 参数slow_query_log,表示是否开启慢查询日志,ON或者1表示开启,OFF或者0表示关闭。
- 参数long_query_time,设置慢查询的阈值,MySQL5.7版本支持微秒级。
- 参数slow_query_log_file,慢查询文件的存放路径。
- 参数log_queries_not_using_indexes,表示是否将非索引查找的SQL也记录到慢查询文件中未使用索引的 SQL 语句上限,0 表示没限制。
- 参数 log_throttle_queries_not_using_indexes,表示每分钟记录到慢查询文件中未使用索引的 SQL 语句上限,0 表示没限制。
- 参数 max_execution_time,用来控制 SELECT 语句的最大执行时间,单位毫秒,超过此值MySQL 自动 kill 掉该查询。
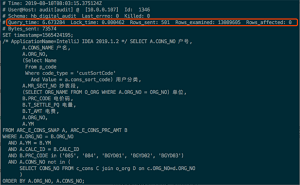
如上图所示是一个慢查询的例子,通过这个例子你可以看到慢查询文件中记录了哪些信息。包括了慢SQL产生的时间,SQL源自的IP和对应的数据库用户名,以及访问的数据库名称;查询的总耗时,被lock 的时间,结果集行数,扫描的行数,以及字节数等。当然还有具体的 SQL 语句。
分析慢查询常用的工具有:
explain;
Mysql dump slow,官方慢查询分析工具;
pt-query-digest,Percona公司开源的慢查询分析工具;
vc-mysql-sniffer,第三方的慢查询抓取工具;
pt-kill,Percona公司开源的慢查询kill工具,常用于生产环境的过载保护。
这里重点介绍pt-query-digest,它是用于分析MySQL慢查询的一个常用工具,先对查询语句的条件进行参数化,然后对参数化以后的查询进行分组统计,统计出各查询的执行时间、次数、占比等,同时把分析结果输出到文件中。也可以结合 Anemometer 工具将慢查询平台化展示。
如何优化SQL
-
全表扫描还是索引扫描。对于小表来说,二者IO调用次数和返回时间相差不大;但对于大表,如果全表扫描,那么查询返回的时间就会很长,就需要使用索引扫描加快查询速度。但并不是要求DBA根据每一种查询条件组合都要创建索引,索引过多也会降低写入和修改的速度,而且如果导致表数据和索引数据比例失调,也不利于后期的正常维护。
-
如何创建索引,在哪些列上建立索引适合业务需求?一般情况下,你可以在选择度高的列上创建索引,也可以在status列上创建索引。创建索引时,要注意避免冗余索引,除非一些特殊情况外。如index(a,b,c)和index(a),其中a的单列索引就是冗余索引。
-
创建索引以后,尽量不要过频修改。业务可以根据现有的索引情况合理使用索引,而不是每次都去修改索引。能在索引中完成的查找,就不要回表查询。比如SELECT某个具体字段,就有助于实现覆盖索引从而降低IO次数,达到优化SQL的目的。
-
多表关联的SQL,在关联列上要有索引且字段类型一致,这样MySQL在进行嵌套循环连接查找时可以使用索引,且不会因为字段类型不一致或者传入的参数类型与字段类型不匹配的情况,这样就会导致无法使用索引,在优化SQL时需要重点排查这种情况。另外索引列上使用函数也不会涉及索引。多表关联时,尽量让结果集小的表作为驱动表,注意是结果集小的表,不是小表。
-
在日常中你会发现全模糊匹配的查询,由于MySQL的索引是B+树结构,所以当查询条件为全模糊时,例如‘%**%’,索引无法使用,这时需要通过添加其他选择度高的列或者条件作为一种补充,从而加快查询速度。当然也可以通过强制SQL进行全索引扫描,但这种方式不好,尽量不要在SQL中添加hints。对于这种全模糊匹配的场景,可以放到ES或者solr中解决。尽量不要使用子查询,对子查询产生的临时表再扫描时将无索引可查询,只能进行全表扫描,并且MySQL对于出现在from中的表无所谓顺序,对于where中也无所谓顺序,这也是可以优化SQL的地方。
-
另外orderby/groupby的SQL涉及排序,尽量在索引中包含排序字段,并让排序字段的排序顺序与索引列中的顺序相同,这样可以避免排序或减少排序次数。
-
除此之外,复杂查询还是简单查询?貌似总会面临这样的疑问和选择。不要总想着用一个SQL解决所有事情,可以分步骤来进行,MySQL也十分擅长处理短而简单的SQL,总体耗时会更短,而且也不会产生臃肿的 SQL,让人难以理解和优化。
常用的SQL编写规范如下所示。
- SELECT只获取必要的字段,禁止使用SELECT*。这样能减少网络带宽消耗,有效利用覆盖索引,表结构变更对程序基本无影响。
- 用IN代替OR。SQL语句中IN包含的值不宜过多,应少于1000个。过多会使随机IO增大,影响性能。
- 禁止使用orderbyrand()。orderbyrand()会为表增加几个伪列,然后用rand() 函数为每一行数据计算 rand() 值,最后基于该行排序,这通常都会生成磁盘上的临时表,因此效率非常低。建议先使用 rand() 函数获得随机的主键值,然后通过主键获取数据。
- SQL中避免出现now()、rand()、sysdate()、current_user()等不确定结果的函数。在语句级复制场景下,引起主从数据不一致;不确定值的函数,产生的SQL语句无法使用QUERY CACHE。