目录
1. 开篇叨叨
1.1 带着问题读文章
Hash是什么
HashMap的继承关系
HashMap的底层数据结构是什么
JDK 1.8以后做了什么优化
HashMap如何扩容的
HashMap的容量为什么一定是2的n次方
HashMap如何解决冲突的
HashMap的检索性能怎么样
HashMap线程安全吗,为什么
hash值是如何计算的
2. HashMap是什么
2.1 为什么会有HashMap
2.2 哈希表原理是什么?
2.3 Java HashMap介绍
2.4 Java HashMap底层结构是什么
2.4.1 JDK 1.7之前的HashMap结构
2.4.1 JDK 1.7之前的结构存在的问题
2.4.2 JDK 1.8的HashMap结构
3. 小记
1. 开篇叨叨
这接下来的文章中,我们会一起探究一下Java里面的Map相关类。Map里面的HashMap,ConcurrentHashMap等都是我们在工作中常用的类,搞清楚其用法和基本原理,对工作 or 找工作都甚是重要。
今天首先开始讲解HashMap,在看以下的文章之前,先抛几个问题,也是常见的面试点,带着问题效果会更好。
1.1 带着问题读文章
Hash是什么
HashMap的继承关系
HashMap的底层数据结构是什么
JDK 1.8以后做了什么优化
HashMap如何扩容的
HashMap的容量为什么一定是2的n次方
HashMap如何解决冲突的
HashMap的检索性能怎么样
HashMap线程安全吗,为什么
hash值是如何计算的
2. HashMap是什么
2.1 为什么会有HashMap
回答这个问题之前,我们来想一想,数据结构里面,都有哪些基本的数据结构?
- 数组:数组是一段连续的存储空间,可以很容易(O(1)的时间复杂)度获取元素:只需要知道它的位置(index),就可以直接拿出数据来。但是插入删除查找就比较耗时了(需要O(n)),因为查找需要逐一对比数据,删除/插入需要挪动数据的位置。
- 链表:链表的存储空间可以是离散的,它和数组正好相反,获取元素需要O(n),插入删除元素容易,只需要更改指向的指针就好了。
【如果上述不懂,可以看看数据结构书】
那么问题来了:程序员无论做什么,总是希望快一点,更快一点,有没有结合二者优势的数据结构呢?
- 插入快
- 查找快
- 获取快
答案是显而易见的,那就是:
- 哈希表
2.2 哈希表原理是什么?
哈希表是一种数据结构,可以能做到查询存储修改各种快,其原理就在:
使用当前数据的信息,通过某种方法把这些信息转换为一个数组的index,然后通过数组的下标来获取元素。
这里的某种方法的计算可以描述为:
index = f(数据信息)
这里的f就是我们常说的hash函数。举个例子,我们要存储一个名叫张三的人,那么:
f(张三)= 3,那么就在index = 3的地方插入张三这个人。
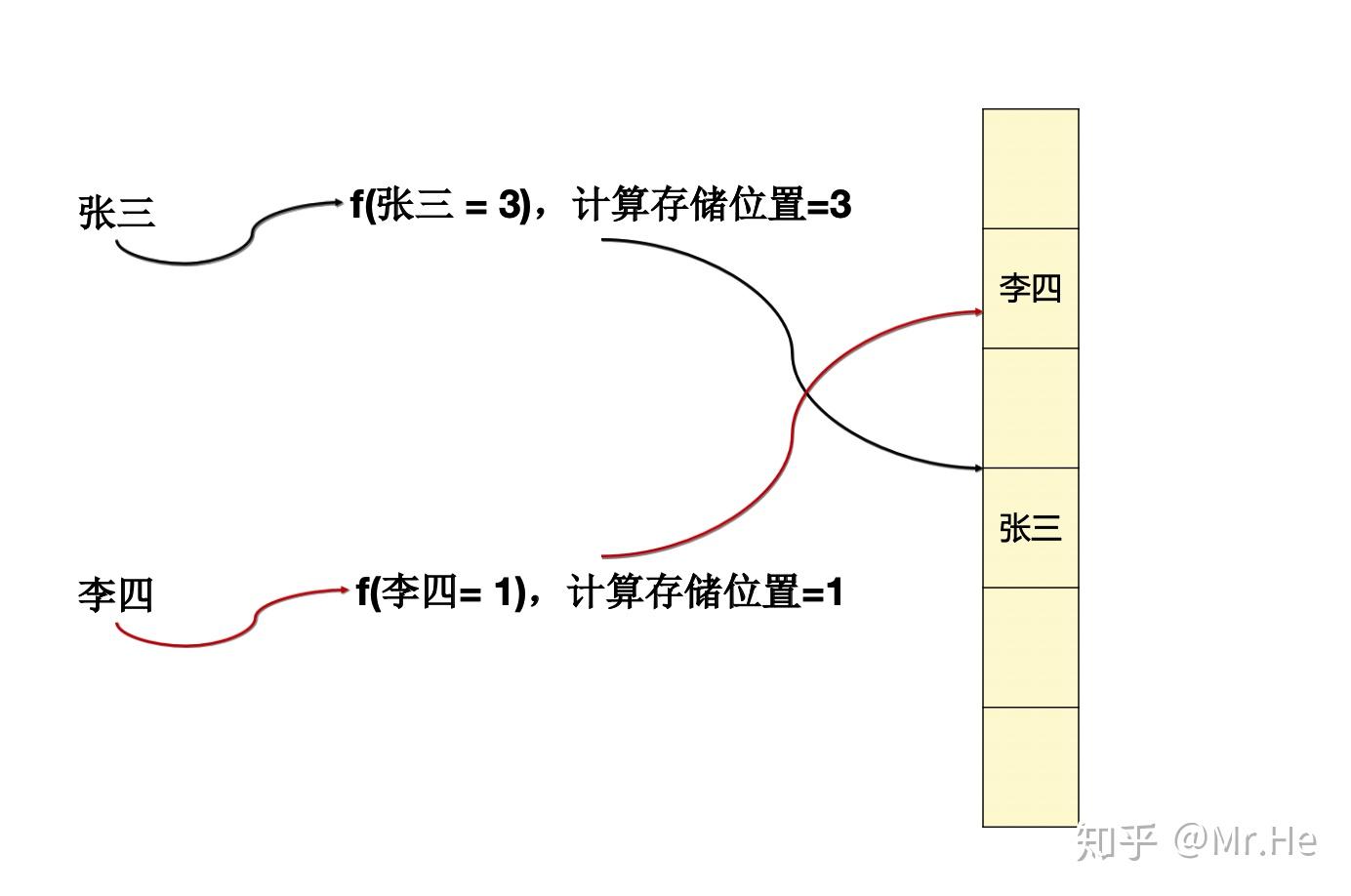
查询的时候一样如此,所以就可以做到非常快!!!
所以划重点了,hash函数就是通过算法将数据转换为特定值的计算方法。
2.3 Java HashMap介绍
在Java里面同样有哈希表的数据结构,它就是HashMap,用的时候导入包名:
import java.util.HashMap
它是Java内置的集合类,它的继承体系为:
- AbstractMap
- Map
- Cloneable, Serializable
这里和ArrayList和LinkedList不同,它不继承接口Collection,这里大家了解一下就好了。
到此我们正式给出HashMap非常官方的定义/特性:
- HashMap是存储Key,Value的数据结构,它的底层使用的是哈希表的原理。它存储数据可以是任何是数据类型,包括null
- 它的Key-value在Java里面又叫Entry
- 它存储数据的时候,先通过Key计算hash值,找到存储的位置,然后出入数据
- 它获取数据的时候,也是通过Key计算hash值,找到存储位置,取出数据
- 存储和获取数据的时间都非常快,计算机里面一般称为常量时间
2.4 Java HashMap底层结构是什么
2.4.1 JDK 1.7之前的HashMap结构
细心的同学发现,通过2.2小节的讲解,HashMap貌似需要使用数组来实现,要不然我们怎么使用位置信息(index)来直接获取数据信息呢?
说对了,底层确实用了数组,而且Java里面,这个数组还是一个叫Entry[]的数组,Entry存储了Key和Value。但是不同的数据信息计算的index有没有可能相等?:
index = f(数据信息1)
index1 = f(数据信息2)
index1 和 index有没有可能都等于一个数,比如 9?
当然有可能!!!这个和hash函数的设计有关系,但是再完美的hash函数都会出现冲突(这个叫hash冲突,后面讲)
那冲突了怎么办呢?最直观的想法就是,把冲突的元素存到一块去。
Java里面的HashMap在JDK1.7之前,如果冲突了,就在冲突的位置后面挂一个链表,来看图示:
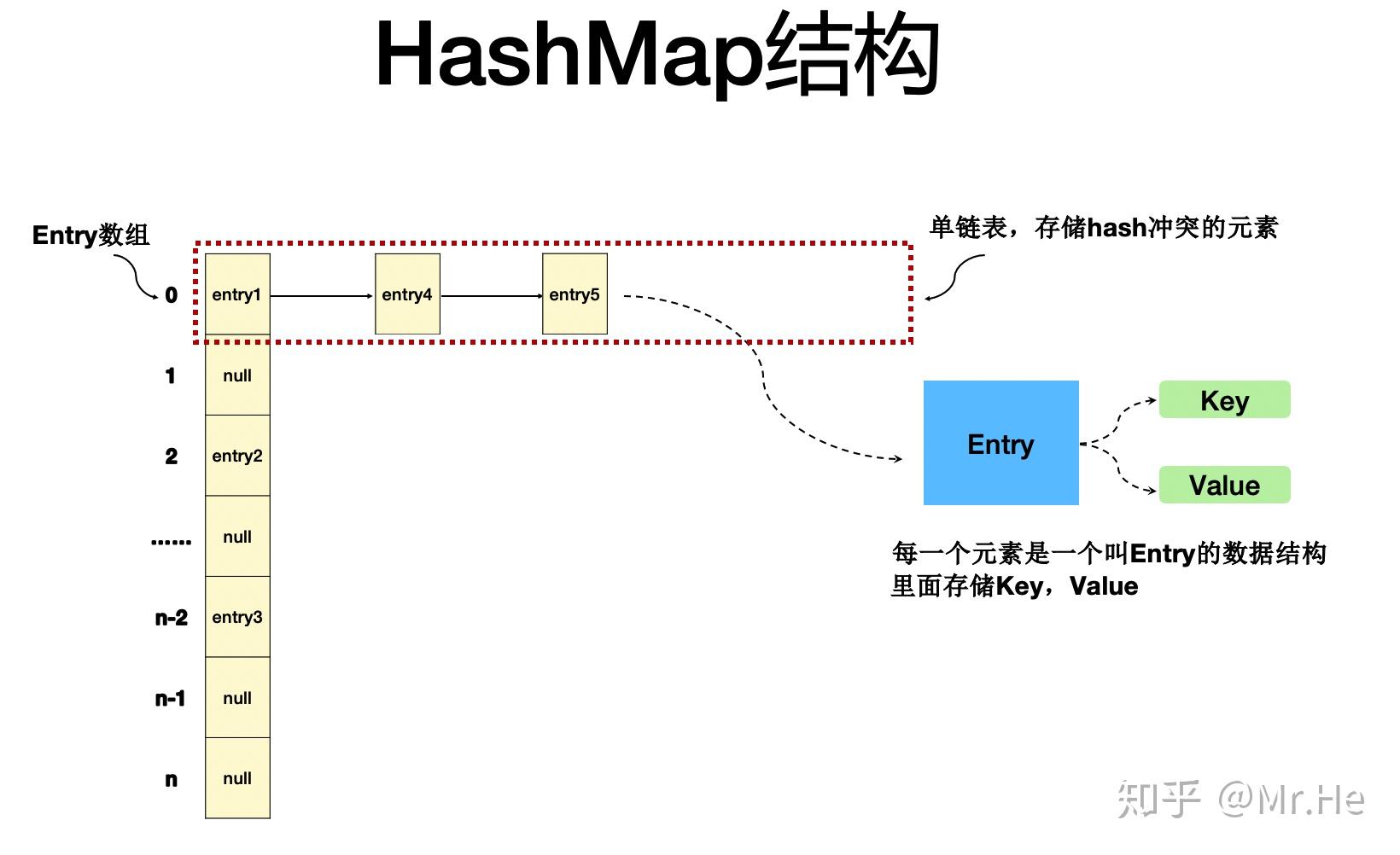
这个时候,存储/查找是这样的:
- 先计算得到其位置,比如图中index=0的地方
- 然后遍历这个单链表,做一一比较,得到要查询的数据
2.4.1 JDK 1.7之前的结构存在的问题
如果冲突的情况比较多,那么后面挂的数据就会比较多,也就是链表比较长,根据上一小节的情况,以及链表的特性,查找就慢了,这个时候HashMap就偏离设计的初衷了
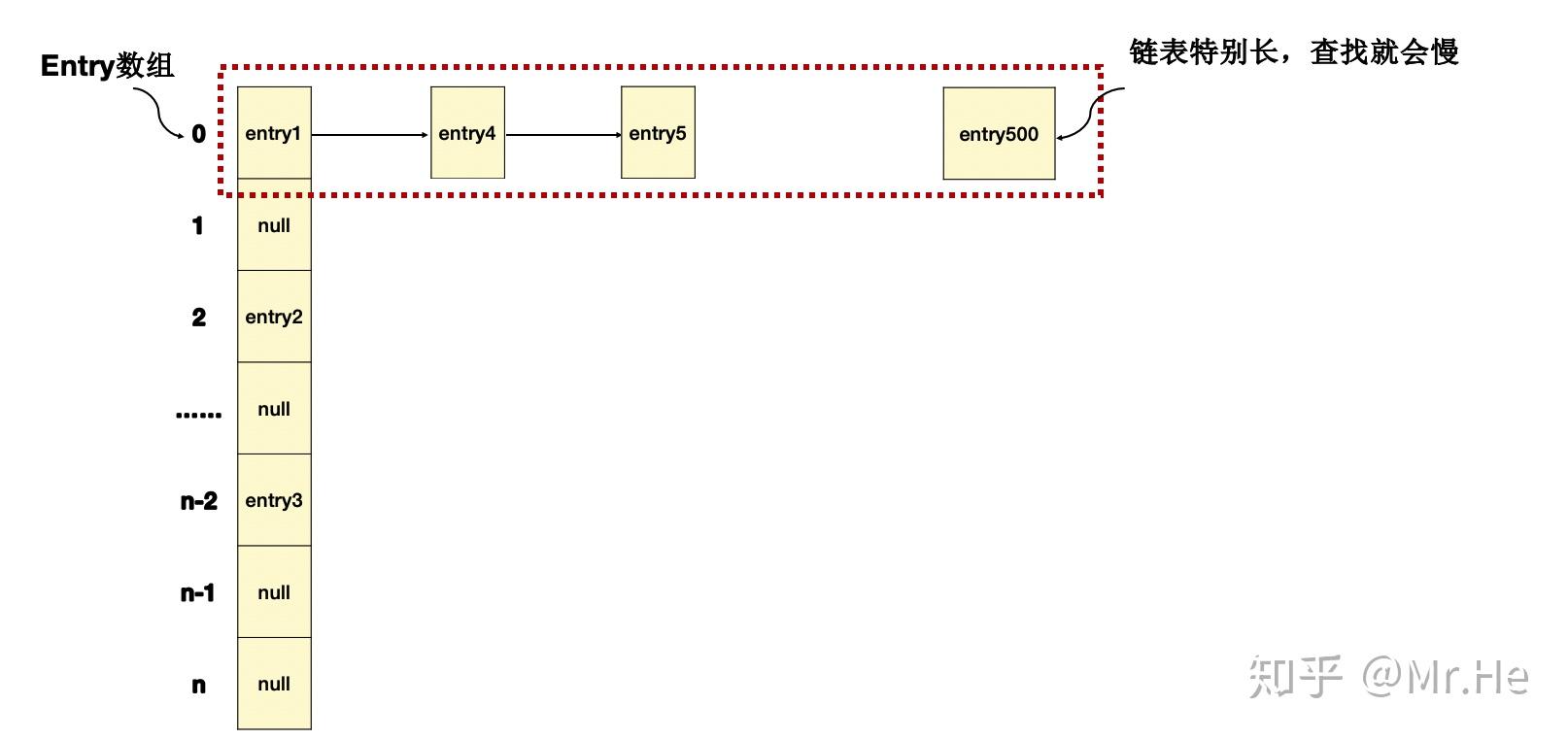
那怎么办?
2.4.2 JDK 1.8的HashMap结构
最直观的想法,就是冲突的时候,把链表替换为一个查找效率高的数据结构。那有没有这样的数据结构呢?
当然有,那就是红黑树!!!(现在只需要知道,这种数据结构,是一种高效的查找数据结构就好了)
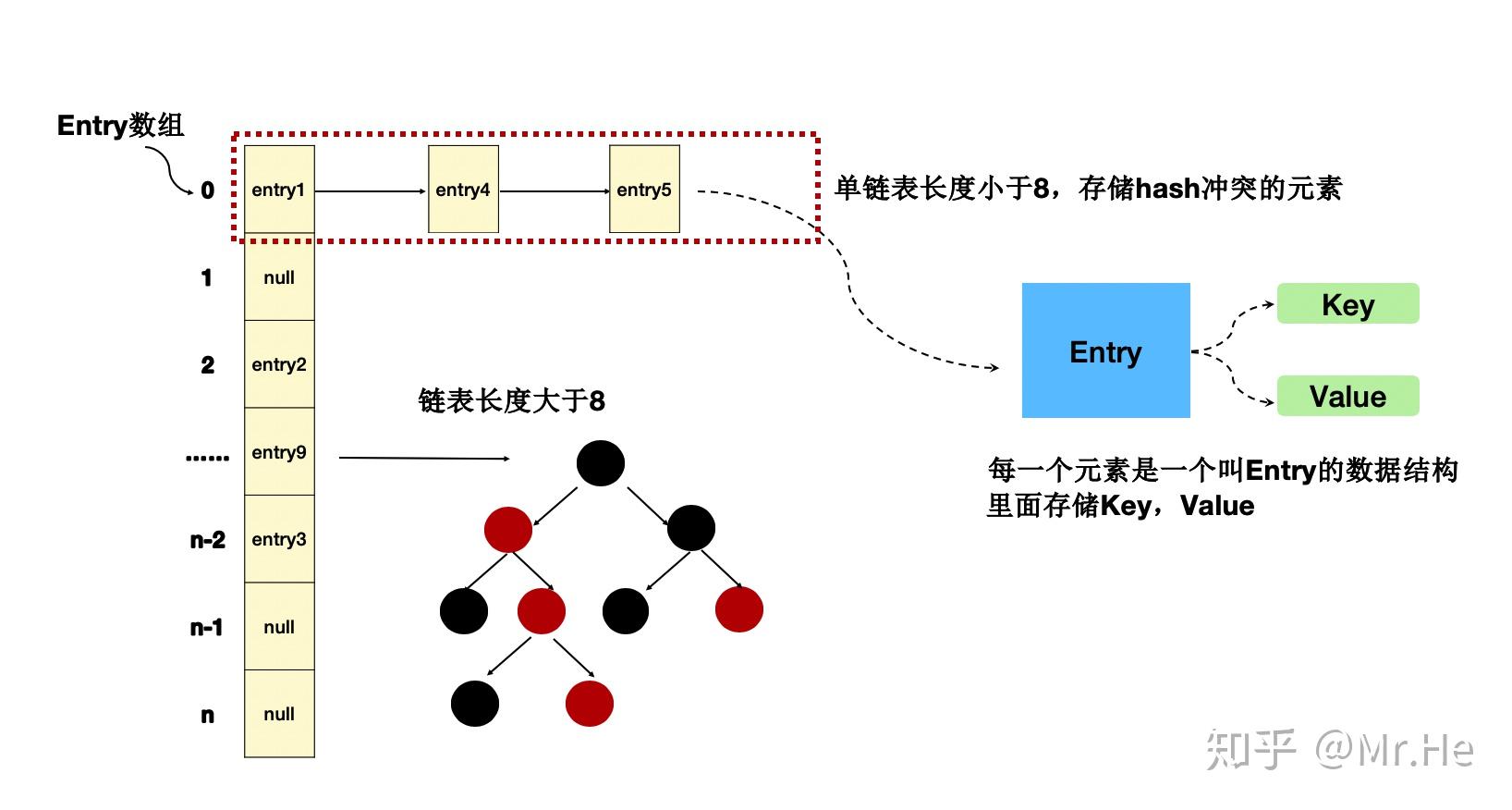
但是在JDK1.8里面,也不是所有情况都会使用红黑树,其为了各种性能考虑:
- 只有在链表长度大于8的情况下,使用红黑树
- 其他的情况,还是链表
3. 小记
今天讲解了哈希表的基本原理,和Java HashMap的基本知识,后续会带来HashMap的基本使用方法和它的常见问题分析,这些都是面试的时候常见的。
大爷们,喜欢的就随手给个赞吧**!**